Why is Big Data a complex and scary concept? Many may argue it is complex because it is unstructured. We believe it is complex because of its dynamic nature. Whittling down the ceaseless generation of incomprehensible data to an understandable form makes it an insurmountable task. And to make matters worse, the raw data keeps piling up because of the painfully slow yield of analyzed data at the other end.
Part of the problem lies in our approach to analyze data. We try to analyze the system as a whole. This creates technological impracticality as it is impossible to treat such large volumes which keeps growing with each passing minute. For instance, the Facebook, Twitter and CNRS alone generate 17 terabytes of information every day. Add to this the data generated every second by biometric meters, appliances, telephones, scientific instruments.
Treating this colossal mass of data at our disposal is unthinkable as well as meaningless. Overdependence on data scientists is the other part of the problem. Often this causes the two key players i.e. system interpreters and data scientists to be out of sync, owing to which actionable insights get overlooked or lost.
Simplifying Big Data
Limit the Scope
Limiting the scope of big data analysis can untangle many a knots. This means identifying the right data that needs to be analyzed. The objective is to bring down raw data sets of heterogeneous dimensions to smaller sets of homogeneous dimensions without losing the properties that matter.
Limiting the scope would lead to the creations of templates for standard data input, making data capture and analysis simpler and faster. It would also lead to finding meaningful ways to package the different data architectures and tools. To ensure this, organizations should be specific about the business problems they want to solve or opportunities they hope to exploit. They need to be creative in identifying usable data from all the available sources of information.
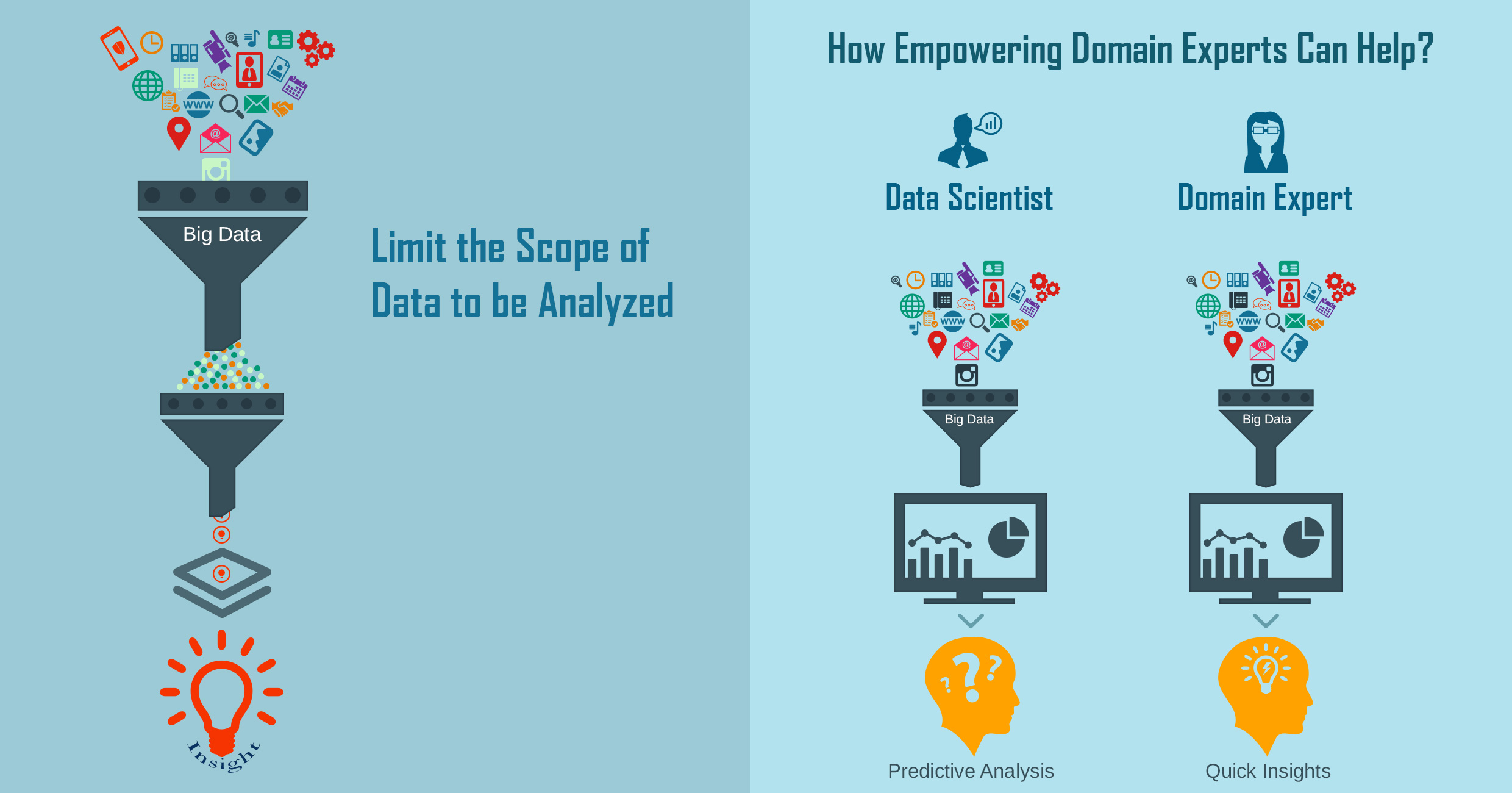
Empower Domain Experts
A lot of simplification can be achieved by empowering domain experts to drive the machine learning aspect of big data analysis. The role of a data scientist is to feed meaningful combinations of the data into the machine so that effective predictive analysis can be carried out fast. What if the data scientist is removed and replaced by the domain expert? The domain expert will be in a position to directly encode their domain ideas into the system. This would lead to templatizing data combination on domain basis, helping the experts experiment with ideas and get quick insights. Also, it would lead to the removal of an additional process layer thereby cutting down the process time significantly.
So, to get the most out of big data organizations need to look for creative ways to identify usable data, and make this data available directly to business leaders. Only then organizations will be able to make the make the most of big data.
 Prev
Prev

